
Redis基础数据结构
redis基本类型使用场景都懂了
学习 Redis 基础数据结构,不讲虚的。
一个群友给我发消息,“该学的都学了,怎么就找不到心意的工作,太难了”。
很多在近期找过工作的同学一定都知道了,背诵八股文已经不是找工作的绝对王牌。企业最终要的是可以创造价值,或者首先需要干活的人,所以实战很重要。今天这篇文章就是给大家分享一下如何在我们实战生产中使用 redis。
如果不了解 redis 的同学,可以先学习之前的 redis 入门教程。reids 从黑铁到王者
...
⚠️注意:命令不区分大小写,而 key 是区分大小写的。
String
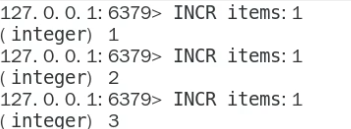
String 作为最基本的类型,就是普通的 get、set,做简单的 key - value 存储
应用场景:
比如在商品编号的生成、订单编号的生成(当然现在很少用到了,毕竟现在这种编号已经不足以承载当今的电商服务)
商品编号生成 是否喜欢的文章

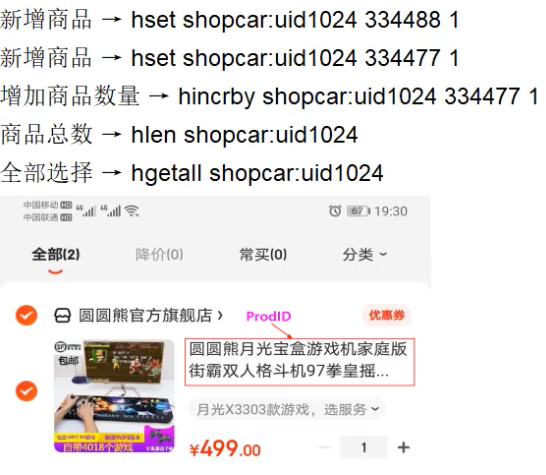
Hash
- Hash 是一个类似于 Map 的结构,我们可以将整个对象缓存到 redis 中(这个对象不可以在嵌套其他对象),每次读写缓存时可以直接操作 hash 这个对象里的某个字段值。
- 类似于 Java 中的
Map<String, Map<Object, Object>>
语法:
redis 127.0.0.1:6379> HSET KEY_NAME FIELD VALUE- 应用场景:购物车早期,当前小中厂可用
List
List 就是编程中常用的字符串列表,列表的最大长度是 2^32 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
比如文章列表、粉丝列表等需要缓存的场景。
可以作为一个单项或者双向队列,lpush、rpop、rpush、lpop。
LRANGE命令可以指定元素获取区间,实现分页查询,比如微博新闻的列表页面、一些高性能查询的场景应用场景:
- 循环抓取新闻的主站点列表
redis 127.0.0.1:6379> RPOPLPUSH SOURCE_KEY_NAME DESTINATION_KEY_NAMEredis 127.0.0.1:6379> RPOPLPUSH news:list:websites news:list:websites- 分页查询网站首页的新闻资讯,查询第 0~10 条的数据。
lrange article:list 0 10Set
无序列表,自动去重。
和 Java 中的 hashset 一样,当需要进行大量数据的去重、之前你是基于 JVM 在内存去重,现在多机器部署的程序可以基于 redis 去重。
比如需要进行交集计算,两个自媒体账号属于同一个人、他的粉丝一共有多少,需要将两个账号粉丝进行去重统计。当然,并集、差集都可以这样操作。
应用场景:
微信抽奖小程序
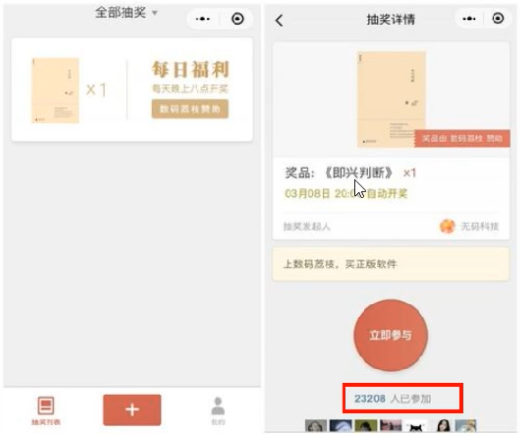
image-20210111131808595 
image-20210111131949452 微信朋友圈点赞

image-20210111133506484 微博好友关注社交关系
共同关注的人:我去到 gakki 的微博,马上获得我和 gakki 共同关注的人

image-20210111133650920 我关注的人也关注他(大家爱好相同)

image-20210111133831044 qq推荐可能认识的人

image-20210111133958782
SortedSet
排序的 set,去重但是可以排序,写进去的时候给一个分数,自动根据分数排序,这个可以玩儿很多的花样,最大的特点是有个分数可以自定义排序规则。
比如说你要是想根据时间对数据排序,那么可以写入进去的时候用某个时间作为分数,人家自动给你按照时间排序了。
排行榜:将每个用户以及其对应的什么分数写入进去,
zadd board score username,接着zrevrange board 0 99,就可以获取排名前100的用户;zrank board username,可以看到用户在排行榜里的排名。应用场景:
根据商品销售对商品进行排序显示。

image-20210111140054296 抖音热搜

image-20210111140639166
下面这三个你可能不太熟悉,耐心看完,这是通俗易懂的。
Bitmap
Bitmap 大家可能有些陌生,什么是 Bitmap 呢?
Bitmap 的底层数据结构用的是 String 类型的 SDS 数据结构来保存位数组,Redis 把每个字节数组的 8 个 bit 位利用起来,每个 bit 位 表示一个元素的二值状态(不是 0 就是 1)。
可以将 Bitmap 看成是一个 bit 为单位的数组,数组的每个单元只能存储 0 或者 1,数组的下标在 Bitmap 中叫做 offset 偏移量。
8 个 bit 组成一个 Byte,所以 Bitmap 会极大地节省存储空间。 这就是 Bitmap 的优势。
比如判断用户是否登录状态,可以将用户 id 映射为一个唯一 id 编号,将 bit 位映射为 1。
布隆过滤器底层选用的数据结构就是 bitmap(在程序中也用 bitset)。
应用场景:
用户每月签到情况。在签到统计中,每个用户每天的签到用 1 个 bit 位表示,一年的签到只需要 365 个 bit 位。一个月最多只有 31 天,只需要 31 个 bit 位即可。
1. 编号 9527 的用户在 2024 年 1 月 16 号打卡。 SETBIT uid:sign:9527:202401 15 1 2. 判断是否打卡。 GETBIT uid:sign:9527:202401 15 3. 统计 1 月份打卡次数,使用 `BITCOUNT` 命令。该指令用于统计给定的 bit 数组中,值 = 1 的 bit 位的数量。 BITCOUNT uid:sign:9527:202401
HyperLogLog
HyperLogLog 并非 Redis 一家独有,Redis 只是基于 HyperLogLog 算法实现可一个 HyperLogLog 数据结构,并用该数据结构提供基数统计的功能。其优势就是可以做到只需要 12 kb 的空间大小,就可以实现接近 2^64 量级的基数统计。
HyperLogLog 数据结构并不会保存真实的元数据,所以其核心就是基数估算算法 在工程实践中,通常会用于 App 或页面的 UV 统计。
HyperLogLog 是一种基数估算算法。所谓基数估算,就是估算在一批数据中,不重复元素的个数有多少。
应用场景:
计算
javapub.net.cn网站的日活跃用户。通过 ip 在程序中用 HashSet 分析、如果有几百万用户,占用存储无疑是很大的。但是用了 HyperLogLog,事情变得如此简单。因为存储日活数据所需要的内存只有 12K。HyperLogLog只提供了 3 个简单的命令。1. 添加元素到 HyperLogLog 中。 PFADD key element [element ...] 127.0.0.1:6379> pfadd website:javapub:uv 39.1.2.0 2. 返回给定 HyperLogLog 的基数估算。 PFCOUNT key [key ...] 127.0.0.1:6379> pfcount website:javapub:uv 3. 将多个 HyperLogLog 合并为一个 HyperLogLog。PFMERGE destkey sourcekey [sourcekey ...] 127.0.0.1:6379> pfmerge website:javapub:uv website:javapub-2:uv
GEO
看到这个名字就知道是经纬度坐标相关。需要涉及到地图的业务才会使用。
Redis GEO 有如下操作方法:
- geoadd:添加地理位置的坐标。
- geopos:获取地理位置的坐标。
- geodist:计算两个位置之间的距离。
- georadius:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。
- georadiusbymember:根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合。
- geohash:返回一个或多个位置对象的 geohash 值。
应用场景:
计算 Palermo 与 Catania 之间的距离:
redis> GEOADD Sicily 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania" (integer) 2 redis> GEODIST Sicily Palermo Catania "166274.1516" redis> GEODIST Sicily Palermo Catania km "166.2742" redis> GEODIST Sicily Palermo Catania mi "103.3182" redis> GEODIST Sicily Foo Bar (nil) redis>